CAP Theorem
What is it?
At times when the network is working correctly, a system can provide both consistency (ie. linearizability) and total availability. When a network fault occurs, you have to choose between either linearizability or total availability.
- Thus, a better way of phrasing CAP would be "when a network partition occurs, a distributed system must choose between either consistency or availability".
- A more reliable network needs to make this choice less often, but at some point the choice is inevitable.
- note: this seems to be at least somewhat of a controversial tone, given that SQL databases occupy CA. This view above would state that CA systems are incoherent, though this opinion might not appear to be reputable, given the prevalence of relational databases.
- regarding CA systems then, what CAP theorem would argue is that these systems have an inherent weakness, which is that in the case of a network partition, they will be forced to give up either consistency or availability.
CAP is sometimes presented as Consistency, Availability, Partition tolerance: pick 2 out of 3. Unfortunately, putting it this way is misleading because network partitions are a kind of fault (due to the failure of network devices), so they aren’t something about which you have a choice: they will happen whether you like it or not.
Why must it choose between availability and consistency?
The reason the system must choose is because if there is a network partition, different parts of the system may result in having different views of the data.
- If the system chooses to prioritize consistency, it will ensure that all nodes have the same view of the data, but it may sacrifice availability to all clients, since some nodes may be unavailable due to the partition.
- If the system chooses to prioritize availability, it will continue to provide service to all clients, but it may not be able to ensure that all nodes have the same view of the data, which can lead to inconsistencies.
Consistency (C)
All nodes see the same data at the same time. This means users can read or write from/to any node in the system and will receive the same data. It is equivalent to having a single up-to-date copy of the data.
Depending on the business needs of the application, we may wish to make the trade-off of sacrificing consistency for availability. Say we are implementing a facebook newsfeed. It is acceptable for the application to miss some data points here and there. For instance, if a friend of yours uploads a new post, it's not of critical importance that you get that data right away. That is, if one client is getting its data from a data store that is not up-to-date, then it's not the end of the world (assuming everything can be made up-to-date in a timely manner).
The "C" refers to only one type of consistency: linearizability
The basic idea behind linearizability is simple: to make a system appear as if there is only a single copy of the data.
linearizability is a recency guarantee on reads and writes of a single item in a database.
- In a linearizable system, as soon as one client successfully completes a write, all clients reading from the database must be able to see the value just written. Maintaining the illusion of a single copy of the data means guaranteeing that the value read is the most recent, up-to-date value, and doesn’t come from a stale cache or replica.
Consider that a unique constraint in a relational database requires linearizability
Depending on our use-case, we must decide if our system requires linearizability.
- ex. we may determine that for our flight booking application, the likelihood of two users trying to book the same seat on a flight to be remote, and thus something that we don't feel compelled to account for. In the event of this situation, we might just consider it a business expense to compensate the affected party in another way.
Availability (A)
Availability means every request received by a non-failing node in the system must result in a response. Even when severe network failures occur, every request must terminate. In simple terms, availability refers to a system’s ability to remain accessible even if one or more nodes in the system go down.
- in other words, high availability results from running in a redundant configuration on multiple machines
In an AP (Availability/Partition-tolerant) system, the system is essentially saying “I will get you to a node, but I do not know how good the data you find there will be”; or “I can be available and the data I show will be good, but not complete.”
Partition tolerance (P)
a.k.a robustness
Partition tolerance is the ability of a data processing system to continue processing data even if a network partition causes communication errors between subsystems
- A single node failure should not cause the entire system to collapse.
- A partition is a communication break (or a network failure) between any two nodes in the system, i.e., both nodes are up but cannot communicate with each other.
A partition-tolerant system continues to operate even if there are partitions (ie. communication breakdowns) in the system. Such a system can sustain any network failure that does not result in the failure of the entire network. Data is sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
When to prioritize Availability or Consistency?
Go with eventual consistency if favouring availability, and strong consistency if favouring consistency
Availability
- When eventual consistency can be tolerated.
- When the system needs to remain operational and responsive even in the presence of network partitions or node failures.
- ex. real-time messaging, online gaming, social networks, CDNs, IoT systems
Consistency
- When the application demands strict data consistency and requires all nodes to have a consistent view of the data at all times.
- When data conflicts and inconsistencies can lead to significant negative consequences.
- ex. financial transactions (e.g. banking app), healthcare systems, inventory management, critical infrastructure (e.g. power grids, transportation systems), blockchain
PACELC Theorem
One place where the CAP theorem is silent is what happens when there is no network partition? What choices does a distributed system have when there is no partition?
The PACELC theorem states that in a system that replicates data:
- if there is a partition (‘P’), a distributed system can tradeoff between availability and consistency (i.e., ‘A’ and ‘C’);
- else (‘E’), when the system is running normally in the absence of partitions, the system can tradeoff between latency (‘L’) and consistency (‘C’).
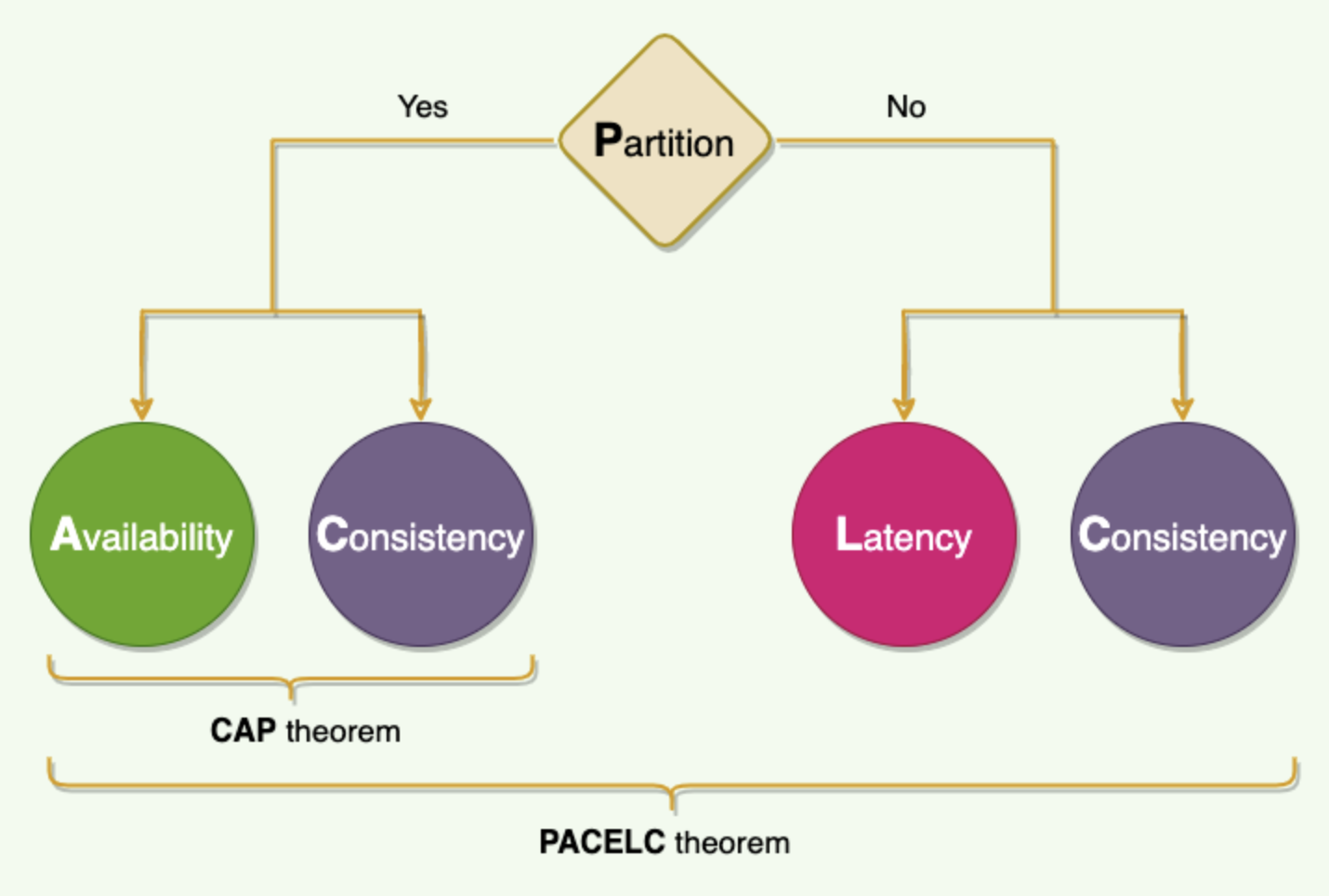
The first part of the theorem (PAC) is the same as the CAP theorem, and the ELC is the extension. The whole thesis is assuming we maintain high availability by replication. So, when there is a failure, CAP theorem prevails. But if not, we still have to consider the tradeoff between consistency and latency of a replicated system.
Examples
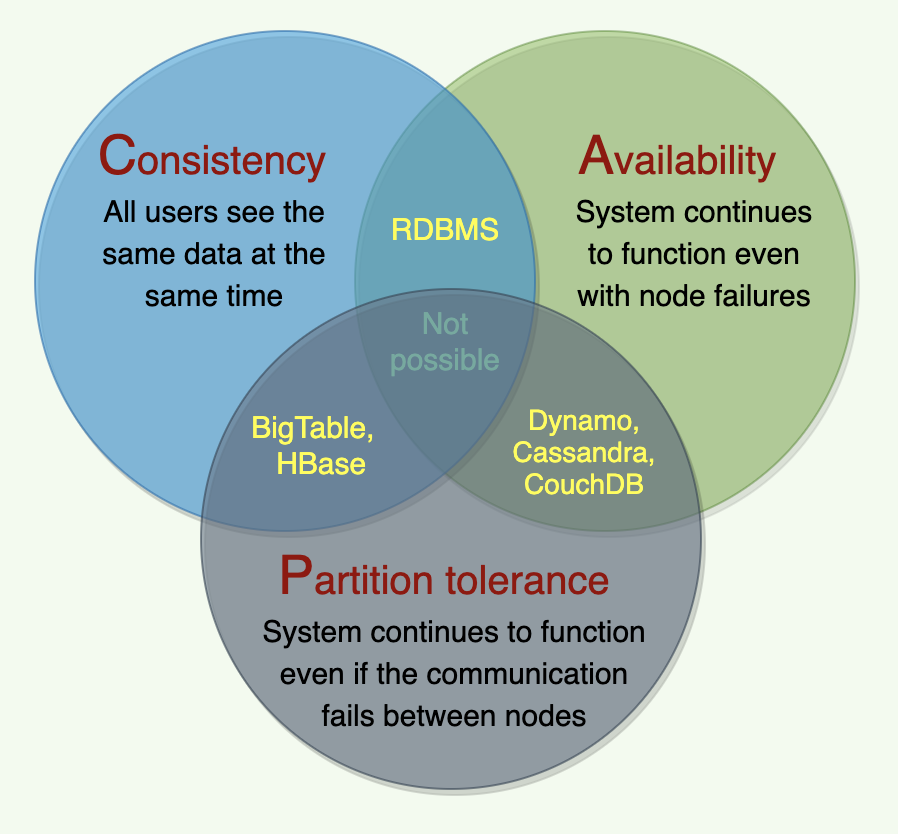
- Relational databases are CP
- CouchDB is AP
- it's Partition-Tolerant, every node is Available at all times, but it's only eventually Consistent.
- DynamoDB and Cassandra are PA/EL systems: They choose availability over consistency when a partition occurs; otherwise, they choose lower latency.
- BigTable and HBase are PC/EC systems: They will always choose consistency, giving up availability and lower latency.
- MongoDB can be considered PA/EC (default configuration): MongoDB works in a primary/secondaries configuration. In the default configuration, all writes and reads are performed on the primary. As all replication is done asynchronously (from primary to secondaries), when there is a network partition in which primary is lost or becomes isolated on the minority side, there is a chance of losing data that is unreplicated to secondaries, hence there is a loss of consistency during partitions. Therefore it can be concluded that in the case of a network partition, MongoDB chooses availability, but otherwise guarantees consistency. Alternately, when MongoDB is configured to write on majority replicas and read from the primary, it could be categorized as PC/EC.
Backlinks