Machine Learning
Machine learning is the ability for computers to learn something without explicitly being programmed to know that thing.
- it is done by turning data into numbers (which are then stored in tensors (Private)), and then passing it into a neural network (which tries to find patterns in those numbers)
- in fact, you can use machine learning for pretty much anything as long as you can convert the inputs into numbers and write the machine learning algorithm that will allow the machine to find the patterns.
- The whole premise of machine learning is to learn a representation of the input and how it maps to the output
- ex. imagine we had an input and an ouput . We are curious to see how these 2 variables relate to each other. Using machine learning, we could reveal that a simple regression formula () lies beneath the relationship. In this case, machine learning is about discovering the nature of that relationship with only the input and the output.
Whereas traditional programming is focused on defining inputs and rules in order to arrive at an output, machine learning is focused on defining inputs and an output, and figuring out the rules necessary to arrive at that output
- ex. we are building a program to cook a roast chicken. The traditional programming paradigm would have us defining the ingredients (ie. inputs) and defining the cooking steps (ie. rules), which yields the cooked meal (ie. output). In machine learning, we define the ingredients, define the output, and the machine learning algorithm will figure out how to make the meal itself.
Use in Machine Learning
Though originally GPUs were built for graphics, Nvidia provides a software platform called CUDA (Compute Unified Device Architecture) which is an API that enables software (like Pytorch) to use GPU for general purpose computing tasks.
GPUs are so fast because they are so efficient for matrix multiplication and convolution
CPUs are latency optimized while GPUs are bandwidth optimized. You can visualize this as a CPU being a Ferrari and a GPU being a big truck. The task of both is to pick up packages from a random location A and to transport those packages to another random location B. The CPU (Ferrari) can fetch some memory (packages) in your RAM quickly while the GPU (big truck) is slower in doing that (much higher latency). However, the CPU (Ferrari) needs to go back and forth many times to do its job (location A pick up 2 packages location B ... repeat) while the GPU can fetch much more memory at once (location A pick up 100 packages location B ... repeat).
So, in other words, the CPU is good at fetching small amounts of memory quickly (5 3 7) while the GPU is good at fetching large amounts of memory (Matrix multiplication: (AB)C). The best CPUs have about 50GB/s while the best GPUs have 750GB/s memory bandwidth. So the more memory your computational operations require, the more significant the advantage of GPUs over CPUs. But there is still the latency that may hurt performance in the case of the GPU. A big truck may be able to pick up a lot of packages with each tour, but the problem is that you are waiting a long time until the next set of packages arrives. Without solving this problem, GPUs would be very slow even for large amounts of data. So how is this solved?
If you ask a big truck to make many tours to fetch packages you will always wait for a long time for the next load of packages once the truck has departed to do the next tour — the truck is just slow. However, if you now use a fleet of either Ferraris and big trucks (thread parallelism), and you have a big job with many packages (large chunks of memory such as matrices) then you will wait for the first truck a bit, but after that you will have no waiting time at all — unloading the packages takes so much time that all the trucks will queue in unloading location B so that you always have direct access to your packages (memory). This effectively hides latency so that GPUs offer high bandwidth while hiding their latency under thread parallelism — so for large chunks of memory GPUs provide the best memory bandwidth while having almost no drawback due to latency via thread parallelism. This is the second reason why GPUs are faster than CPUs for deep learning. As a side note, you will also see why more threads do not make sense for CPUs: A fleet of Ferraris has no real benefit in any scenario.
But the advantages for the GPU do not end here. This is the first step where the memory is fetched from the main memory (RAM) to the local memory on the chip (L1 cache and registers). This second step is less critical for performance but still adds to the lead for GPUs. All computation that ever is executed happens in registers which are directly attached to the execution unit (a core for CPUs, a stream processor for GPUs). Usually, you have the fast L1 and register memory very close to the execution engine, and you want to keep these memories small so that access is fast. Increased distance to the execution engine dramatically reduces memory access speed, so the larger the distance to access it the slower it gets. If you make your memory larger and larger, then, in turn, it gets slower to access its memory (on average, finding what you want to buy in a small store is faster than finding what you want to buy in a huge store, even if you know where that item is). So the size is limited for register files - we are just at the limits of physics here and every nanometer counts, we want to keep them small.
The advantage of the GPU is here that it can have a small pack of registers for every processing unit (stream processor, or SM), of which it has many. Thus we can have in total a lot of register memory, which is very small and thus very fast. This leads to the aggregate GPU registers size being more than 30 times larger compared to CPUs and still twice as fast which translates to up to 14MB register memory that operates at a whopping 80TB/s. As a comparison, the CPU L1 cache only operates at about 5TB/s which is quite slow and has the size of roughly 1MB; CPU registers usually have sizes of around 64-128KB and operate at 10-20TB/s. Of course, this comparison of numbers is a bit flawed because registers operate a bit differently than GPU registers (a bit like apples and oranges), but the difference in size here is more crucial than the difference in speed, and it does make a difference.
As a side note, full register utilization in GPUs seems to be difficult to achieve at first because it is the smallest unit of computation which needs to be fine-tuned by hand for good performance. However, NVIDIA has developed helpful compiler tools which indicate when you are using too much or too few registers per stream processor. It is easy to tweak your GPU code to make use of the right amount of registers and L1 cache for fast performance. This gives GPUs an advantage over other architectures like Xeon Phis where this utilization is complicated to achieve and painful to debug which in the end makes it difficult to maximize performance on a Xeon Phi.
What this means, in the end, is that you can store a lot of data in your L1 caches and register files on GPUs to reuse convolutional and matrix multiplication tiles. For example the best matrix multiplication algorithms use 2 tiles of 64x32 to 96x64 numbers for 2 matrices in L1 cache, and a 16x16 to 32x32 number register tile for the outputs sums per thread block (1 thread block = up to 1024 threads; you have 8 thread blocks per stream processor, there are 60 stream processors in total for the entire GPU). If you have a 100MB matrix, you can split it up in smaller matrices that fit into your cache and registers, and then do matrix multiplication with three matrix tiles at speeds of 10-80TB/s — that is fast! This is the third reason why GPUs are so much faster than CPUs, and why they are so well suited for deep learning.
Keep in mind that the slower memory always dominates performance bottlenecks. If 95% of your memory movements take place in registers (80TB/s), and 5% in your main memory (0.75TB/s), then you still spend most of the time on memory access of main memory (about six times as much).
Thus in order of importance: (1) High bandwidth main memory, (2) hiding memory access latency under thread parallelism, and (3) large and fast register and L1 memory which is easily programmable are the components which make GPUs so well suited for deep learning.
Machine Learning Paradigms
There are three basic machine learning paradigms:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
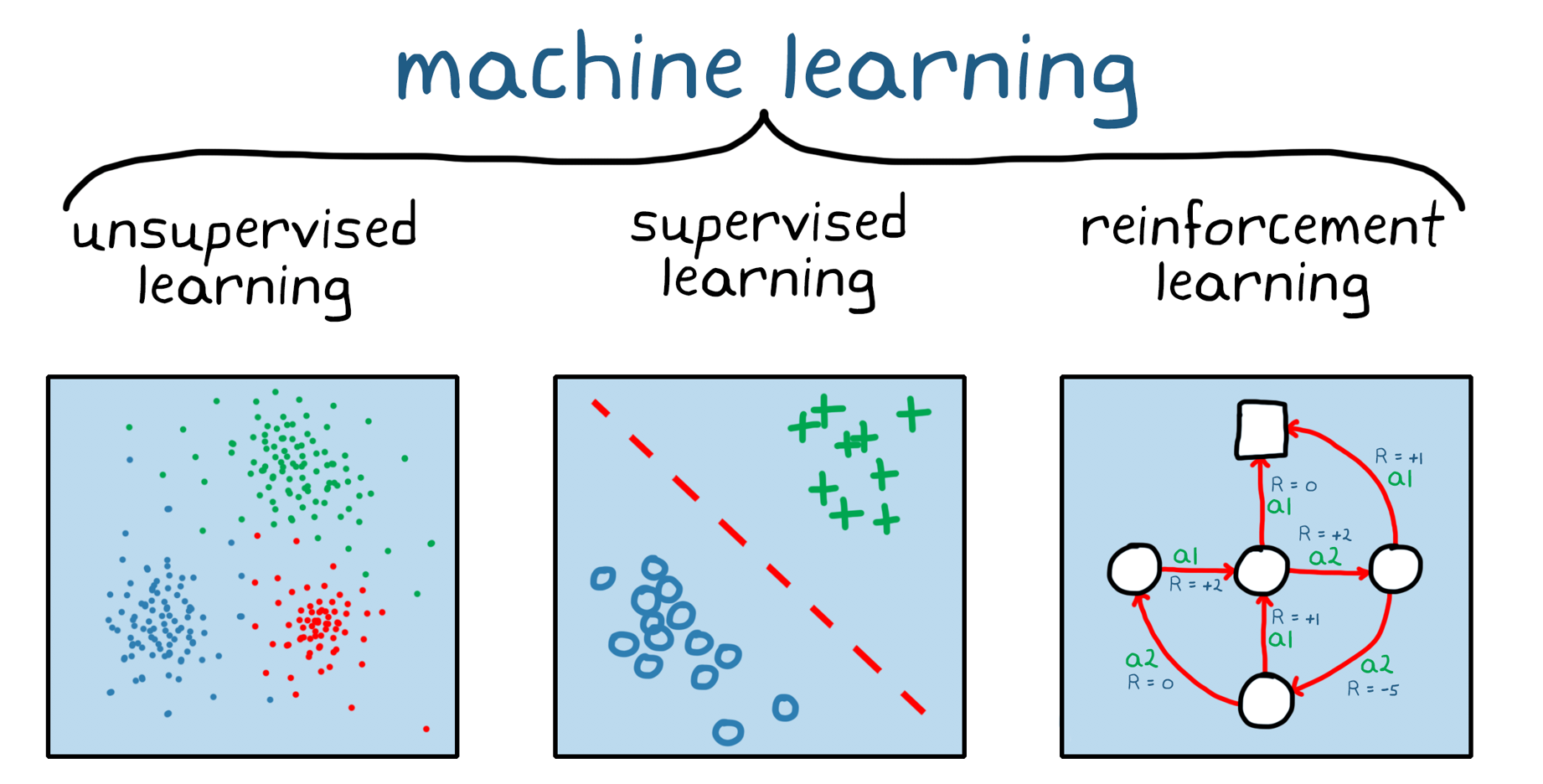
Supervised Learning
Supervised learning is using labeled datasets to train algoritms to classify data or predict outcomes. It does this by iteratively making predictions on the data and adjusting for the correct answer.
- "labeled" means that the rows in the dataset are tagged or classified in some interesting way that tells us something interesting about that data
- ex. "is this a picture of a t-shirt?", "does the picture of the plant have mites on the leaves?"
The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to their correct output.
- it is the job of backpropagation to train a neural network to learn the appropriate internal representation of how an input relates to an output.
In supervised learning, the goal is to predict outcomes for new data. You know up front the type of results to expect.
Supervised learning models tend to be more accurate, but also require much more human intervention
- ex. a supervised learning model can predict how long your commute will be based on the time of day, weather conditions and so on. But first, you’ll have to train it to know that rainy weather extends the driving time.
Classification Model
This method involves us recognizing and grouping ideas/objects into predefined categories
- ex. customer retention - we can make a model that will help us identify customer that are about to churn, allowing us to take action to retain them. We can do this by analyzing their activity
- ex. classify spam in a separate folder from your inbox.
- ex. sentiment analysis to determine the sentiment or emotional polarity of a piece of text, such as a review or a social media post.
Classification models are more suitable when the task involves assigning discrete labels
- ex. Is a given email message spam or not spam?
- ex. Is this an image of a dog, a cat, or a hamster?
Common types of classification algorithms are:
- linear classifiers
- support vector machines
- decision trees
- random forest
Regression Model
This method involves us building an equation using various input values with their specific weights, determined by their overall value of the impact on their outcome. In this way, it helps us understand the relationship between dependent and independent variables
- ex. airlines use these models to determine how much they should charge for a particular flights, using various input factors such as days before departure, day of week, destination etc.
- ex. Weather forecasting - well-suited for regression, since they can estimate a numerical value based on the input features.
Regression models are helpful for predicting numerical values based on different data points, such as sales revenue projections for a given business.
Regression models are more suitable when the output is a continuous value
- ex. What is the value of a house in California?
- ex. What is the probability that a user will click on this ad?
Popular regression algorithms are:
- linear regression
- logistic regression
- polynomial regression
Unsupervised Learning
Using machine learning algorithms to analyze and cluster unlabelled datasets, allowing us to discover hidden patterns/groupings without the need for human intervention.
With an unsupervised learning algorithm, the goal is to get insights from large volumes of new data. The machine learning itself determines what is different or interesting from the dataset.
Unsupervised models still require some human intervention for validating output variables.
- ex. an unsupervised learning model can identify that online shoppers often purchase groups of products at the same time. However, a data analyst would need to validate that it makes sense for a recommendation engine to group baby clothes with an order of diapers, applesauce and sippy cups.
Unsupervised learning models are used for three main tasks:
- clustering
- association
- dimensionality reduction
Clustering
- ex. customer segmentation - it is not always clear how individual customers are similar or different from one another. Clustering algorithms can take into account a variety of information on the customer, such as their purchase history, social media activity, geography, demographic etc., with the goal being to segment similar customers into separate buckets so the company be more targetted with their efforts
Association
- ex. recommendation engines
Dimensionality Reduction
Techniques that reduce the number of input variables in a dataset so we don't let redundant parameters overrepresent the impact on the outcome.
Reinforcement Learning
Reinforcement Learning is semi-supervised learning where we typically have an agent take actions in an environment. The environment will then reward the agent for correct moves, or punish it for incorrect moves
- Through many iterations of this, we can teach a system a particular task
- ex. with self-driving cars
Transfer Learning
Take a pattern that one model has learned from a certain dataset, and apply those learnings to a different model to give us a head start.
- More specifically, it's about leveraging the knowledge learned from one task to aid the learning process in another related task. This can be done within the same model or across models.
- ex. for image classification, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks.
Machine Learning Approaches
Seq2Seq (Sequence to Sequence)
Here, we put one sequence into the model, and get one out
- ex. with Google Translate, we put in our sequence of source language text and get our target language out
- ex. with speech recognition, we put in our sequence of audio waves and get some text out
Classification/regression
Classification is about predicting if something is one thing or another (e.g. if an email is spam or not)
- Computer Vision
- ex. recognizing a truck within a security camera picture.
- In this case, the regression predicts where the corners of the box should be (predicting a number is what regression does), and the classification part would be the machine recognizing whether or not the particular vehicle was the one that did the hit and run.

- In this case, the regression predicts where the corners of the box should be (predicting a number is what regression does), and the classification part would be the machine recognizing whether or not the particular vehicle was the one that did the hit and run.
- ex. recognizing a truck within a security camera picture.
- Natural Language Processing
Datasets
The idea is that we want to split up our data and assign different portions to different sets.
- the main reason to split datasets into Training, Validation, and Test sets is to ensure that we don't overfit our model to the data it was trained on.
Training Set
The training set is the data that the model learns from
This usually encompasses around 60-80% of our data
Validation Set
The validation set is the data that the model gets tuned to
Validation sets are used often, but are not required like training sets and test sets are.
The validation set helps tune hyperparameters and choose the best version of the model
This usually encompasses around 10-20% of our data
Test Set
The test set is the data that the model gets evaluated on to test what it has learned (ie. it is the final evaluation)
The test set should always be kept separate from all other data, since we want our model to learn on training data and then evaluate it on test data to get an indication of how well it generalizes to unseen examples.
This usually encompasses around 10-20% of our data
UE Resources
Children
Backlinks