Apache Flink
What is it?
Apache Flink is a stream processing framework that is scalable and fault-tolerant.
- it is based on the idea that it should not be hard to express simple computations (e.g. calculating an average and then grouping by a certain attribute) while still be able to scale indefinitely, and in a fault-tolerant manner.
- spec: Flink is MapReduce like Apache Hadoop, but with streaming data.
- might not be true.
Flink is a dataflow engine.
- Like MapReduce, they work by repeatedly calling a user-defined function to process one record at a time on a single thread. They parallelize work by partitioning inputs, and they copy the output of one function over the network to become the input to another function.
- Unlike in MapReduce, these functions need not take the strict roles of alternating map and reduce, but instead can be assembled in more flexible ways (these functions are called operators)
Flink's operations can be stateful
- therefore, the processing of one event can depend on the accumulated effect of all the events that came before it.
The dataflows in Flink applications form directed graphs that start with one or more sources (e.g. Kafka, Kinesis), and end in one or more sinks (e.g. Cassandra, DynamoDB, Elastic Search).
- the reason these sources are eligible to be data sources to Flink is because they support low-latency, high throughput parallel reads in combination with rewind and replay – the prerequisites for high performance and fault tolerance.
Flink can enrich data in its streams by using REST APIs and/or making databases queries.
Flink can be written in Java, Python, Scala and SQL
Stream Execution Environment
Every Flink application needs an execution environment. Streaming applications need to use a StreamExecutionEnvironment.
ex.
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
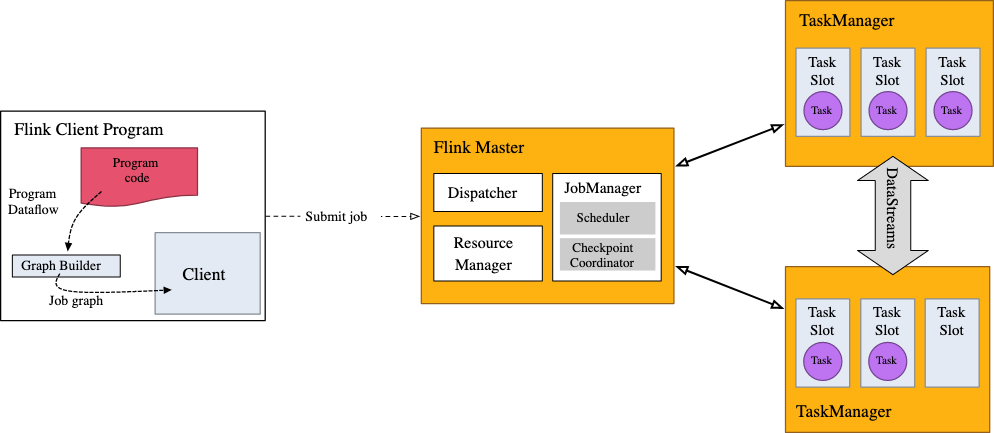
Calls to the DataStream API made in your application will build a job graph that is attached to the StreamExecutionEnvironment
- When
env.execute()is called, this graph is packaged up and sent to theJobManager, which parallelizes the job and distributes slices of it to theTaskManagersfor execution. Each parallel slice of your job will be executed in a task slot. JobManagerdetermines which TaskManager should run the job- therefore
env.execute()must be called in order for our program to run
- therefore
APIs of Flink
Flink has 2 core APIs (DataStream and Dataset), and other high-level APIs built on top of them:
- DataStream API for bounded or unbounded streams of data
- DataSet API for bounded data sets.
- Table API, which is a SQL-like DSL (ie. expression language) for relational stream and batch processing that can be easily embedded in Flink's DataStream and DataSet APIs.
- Async I/O API, which allows users to use asynchronous request clients with data streams.
DataStream API
enables transformations (e.g. filters, aggregations, window functions) on bounded or unbounded streams of data.
available in Java and Scala
DataSet API
enables transformations (e.g., filters, mapping, joining, grouping) on bounded datasets.
As of Flink 1.12 the DataSet API has been soft deprecated. In its place, the Table API and SQL should be used.
- alternatively, use the DataStream API with BATCH execution mode.
available in Java, Scala and Python (experimental)
Table API
A SQL-like expression language for relational stream and batch processing that can be embedded in Flink's Java and Scala DataSet and DataStream APIs
- therefore, a relational Table abstraction is used. Thus, we can do things like select, aggregate, and join
- Tables have a schema attached
Table API uses DataStream and DataSet APIs under the hood.
Async I/O API
Async I/O API is a high-level API that handles the integration with DataStreams, well as handling order, event time, fault tolerance, retry support, etc.
If we were to synchronously access a database within our Flink app, that database interaction would result in massive latency costs.
- therefore, whenever we make database calls in our Flink app, we must use a database client that supports async requests.
- in the unlikely event that the database client doesn't support async requests, we can turn a synchronous client into a limited concurrent client by creating multiple clients and handling the synchronous calls with a thread pool. Naturally, this approach is usually less efficient than a proper asynchronous client.
(In addition to the async db client) three parts are needed to implement a stream transformation with asynchronous I/O against the database:
- An implementation of AsyncFunction that dispatches the requests
- A callback that takes the result of the operation and hands it to the ResultFuture (similar to a Promise)
- Applying the async I/O operation on a DataStream as a transformation with or without retry
How does it work?
Parallelism
Programs in Flink are inherently parallel and distributed across a cluster.
- Flink will basically partition the incoming stream of data and then perform some computation on that subset of data.
- Flink allows us to specify how much parallelism you want for each of these subtasks. To scale up is to simply increase the parallelism of the bottleneck subtask.
- During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks (each of which is independent from one another, and executes in different threads)
- The number of operator subtasks is the parallelism of that particular operator.
- The set of parallel instances of a stateful operator is effectively a sharded key-value store.
- Each parallel instance is responsible for handling events for a specific group of keys, and the state for those keys is kept locally.
The diagram below shows a job. Notice:
- The job runs with a parallelism of two across the first three operators in the job graph, terminating in a sink that has a parallelism of one.
- The third operator is stateful.
- A fully-connected network shuffle is occurring between the second and third operators.
- This is being done to partition the stream by some key, so that all of the events that need to be processed together, will be.
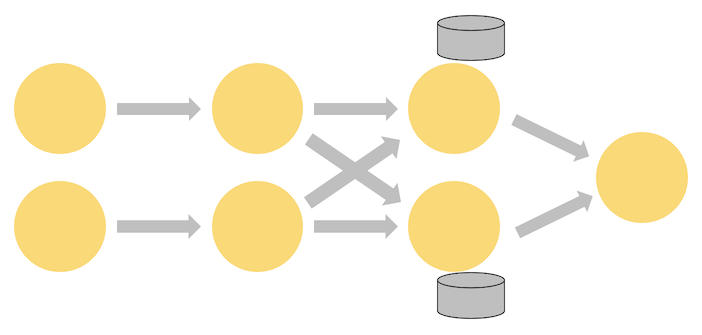
In production, your application will run in a remote cluster or set of containers.
State
Flink offers some compelling features for the state it manages:
- local: Flink state is kept local to the machine that processes it, and can be accessed at memory speed, helping the application achieve high throughput and low-latency.
- durable: Flink state is fault-tolerant (ie. it is automatically checkpointed at regular intervals, and is restored upon failure)
- vertically scalable: Flink state can be kept in embedded RocksDB instances that scale by adding more local disk
- horizontally scalable: Flink state is redistributed as your cluster grows and shrinks
- queryable: Flink state can be queried externally via the Queryable State API.
You can choose to keep state on the JVM heap, or if it is too large, in efficiently organized on-disk data structures.
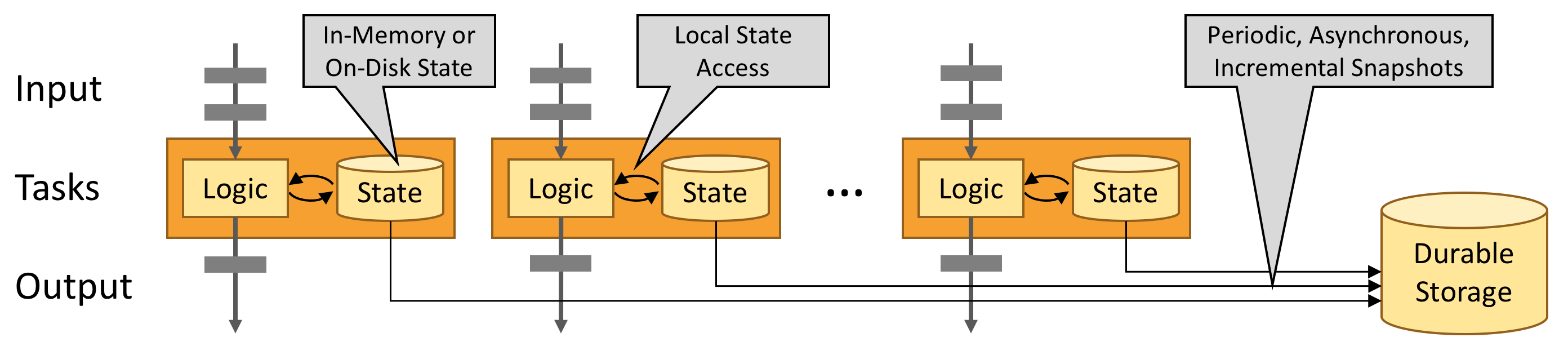
State Snapshots
Flink is able to provide fault-tolerance with state snapshots and stream replay
State Snapshots capture the entire state of the distributed pipeline, recording offsets into the input queues as well as the state throughout the job graph that has resulted from having ingested the data up to that point.
When a failure occurs, the sources are rewound, the state is restored, and processing is resumed. As depicted above, these state snapshots are captured asynchronously, without impeding the ongoing processing.
Fault-Tolerance: checkpoints and savepoints
Distributed checkpoints provide Flink with a lightweight fault-tolerance mechanism.
- A checkpoint is an automatic, asynchronous snapshot of the state of an application and the position in a source stream.
In the case of a failure, a Flink program with checkpointing enabled will, upon recovery, resume processing from the last completed checkpoint, ensuring that Flink maintains exactly-once state semantics within an application.
The checkpointing mechanism exposes hooks for application code to include external systems into the checkpointing mechanism as well (like opening and committing transactions with a database system).
Flink also includes a mechanism called savepoints, which are manually-triggered checkpoints.
- A user can generate a savepoint, stop a running Flink program, then resume the program from the same application state and position in the stream.
Time
Flink explicitly supports three different notions of time:
- event time: the time when an event occurred, as recorded by the device producing (or storing) the event
- use when needing to compute reproducible results (e.g. calculatemaximum price a stock reached in a day) so that the result won’t depend on when the calculation is performed.
- ingestion time: a timestamp recorded by Flink at the moment it ingests the event
- processing time: the time when a specific operator in your pipeline is processing the event
Event Time
If you want to use event time, you will also need to supply a Timestamp Extractor and Watermark Generator that Flink will use to track the progress of event time.
Watermark
Imagine we are building a stream sorter, which simply takes in a stream of events and sorts them by their chronological occurrence (by timestamp). An inherent problem here is that since streams are continuous, we will never really be 100% sure if we have the right order, since events with lower timestamps may technically arrive later on in the stream. At the same time, we can't wait forever. Watermarks solve this problem
Watermarks allow Flink to implement the policy that defines when, for any given timestamped event, to stop waiting for the arrival of earlier events.
- watermark generators insert special timestamped elements into the stream (called watermarks).
- A watermark for time
tis an assertion that the stream is (probably) now complete up through timet. - therefore, our stream sorter program will stop waiting for an event with timestamp prior to 2 once a watermark arrives with a timestamp of 2, or greater.
- A watermark for time
Watermarks give you control over the tradeoff between latency and completeness
- Unlike in batch processing, where one has the luxury of being able to have complete knowledge of the input before producing any results, with streaming you must eventually stop waiting to see more of the input, and produce some sort of result.
Watermarking strategies
"Bounded-out-of-orderness watermarking" - The most simple strategy for watermarking is to assume that there is a maximum delay that we will wait for any "chronologically prior events" to show up
- for most applications a fixed delay works well enough.
Example: Stock market aggregator
Problem statement: Imagine we have a program that consumes a stream of stock market trades and we want to get data on how many trades happen by industry each minute
- this sort of problem has scalability problems built-in, since we can expect there to be a large amount of data, and we will have no forewarning of when trade volume unexpectedly increases.
Implementation: Configure Flink to:
- partition the input stream based on the industry name of the stock
- apply a moving average on a window of 1 minute.
Consider that reading from the stream and applying an AVG calculation are 2 different tasks. Flink allows us to scale up each independently. Therefore, if we determine that trade volume has increased and there are more trades happening per minute, we simply scale up the number of readers. On the other hand, if the number of industries to group by has increased, we simply scale up the number of operators that calculate the AVG.
E Resources
2 types of clusters:
- session cluster
- application cluster
Children
Backlinks