Performance
Load
Load on a system can be described with load parameters, which depend on the architecture of our system. For example:
- requests per second to a web server
- ratio of reads to writes in a database
- number of simultaneously active users in a chat room
- hit rate on a cache
Then we can analyze load in one of 2 ways:
- increase a load parameter and see how it impacts performance
- increase a load parameter and see how much system resources need to be increased to maintain the same performance
Load can be tested with Load Testing
Response Time
Average response time is a poor metric if we want to know "typical response time", since it doesn't tell us how many users experienced any given outlier of a delay time.
- using percentiles is a lot better approach, because then we can make statements such as "90% (ie. p90) of our users experience a response time of 200ms or less"
- to figure out how bad the outliers really are, we can look at high p values, like p99 or even p999 (99.9th percentile)
- using high p values to determine our benchmarks is a good strategy, since users experiencing the longest response times probably have the most data to process, and thus tells us the latest "ceiling" value for how much data we can expect to process.
- also consider that those with the most data might therefore be the most important users, so it's important to keep them happy.
Metrics
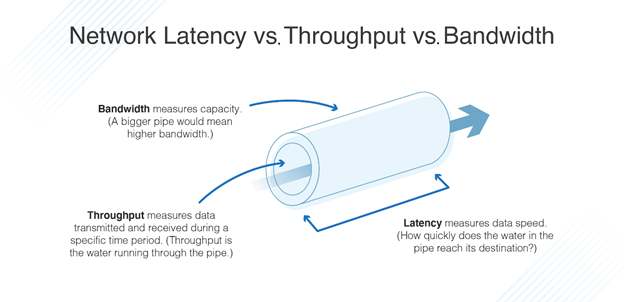
Latency
Latency is the duration that a request is waiting to be handled— during which it is latent, awaiting service.
Low latency can be achieved by:
- Minimizing network latency: This can be done by reducing the distance and number of network hops between the client and server, using CDNs, and using the right network protocols.
- Using fast and efficient algorithms: This involves selecting algorithms that are optimized for speed and efficiency, such as hash tables and binary search.
- Using caching: This involves storing frequently accessed data in memory to reduce the time it takes to retrieve data from disk.
- Optimizing hardware and infrastructure: This involves using high-performance hardware, such as solid-state drives (SSDs) and GPUs, and using infrastructure that is designed for low latency, such as data centers with low-latency networking.
- Using asynchronous programming: This involves designing the system to handle multiple requests simultaneously, using techniques like event-driven programming and non-blocking I/O.
- Choosing the right (low level) programming language
Response Time
Response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays
Backlinks