Replication
Replication in CouchDB works by comparing the source and the destination database to determine which documents differ between the source and the destination database.
- it follows the Changes Feeds on the source and compares the documents to the destination. Once it reaches the end of the feed, the replication process has finished.
- we can set a replication to be
continuous, meaning it will wait for new changes to appear until the task is canceled. - replications can also be paused with checkpoints, and continued. This is helpful is case of a fault.
Changes are then sent in batches to the destination, where they are compared and inform CouchDB if there are conflicts.
If you know Git, then you know how Couch replication works. Replicating is very similar to pushing or pulling with distributed source managers like Git.
- Like Git, Couch documents have a linked-list revision history. If a revision exists in the other's history, then it can be fast-forwarded.
- In Git, if 2 documents have a common ancestor, it's called a fork; in Couch, it's a conflict.
- therefore neither Git or CouchDB have linear lists.
- conflicts in CouchDB do not correspond to conflicts in Git
- a conflict in CouchDB is a divergent revision history
- When a child has multiple parents, Git allows us to merge. CouchDB can be configured to do this via the application code.
- In Git, this is like copying and pasting the changes from branch A into branch B, then committing to branch B and deleting branch A.
When a document is updated, it is given an incremented _rev value
- when an item is deleted (in CouchDB, soft deleted), its
_revvalue will be updated. Since it is considered as a new revision, when a document is deleted on the source, that deletion will be replicated to the target.
Replication tasks can be initiated by either the sending node or the receiving node.
- when the sending node initiates the replication task, it is called push replication
- when the receiving node initiates the replication task, it is called pull replication
- Replication tasks only transfer changes in one direction.
- the easiest way to perform a full sync is to do a "push" followed by a "pull" (or vice versa).
There are three options for controlling which documents are replicated, and which are skipped:
- Defining documents as being local.
- Using Selector Objects.
- allows us to apply business logic through query expressions to determine whether or not a document should be included in the replication. The selector specifies fields in the document, and provides an expression to evaluate with the field content or other data. If the expression resolves to true, the document is replicated.
- selector objects exist on a replication document.
- note: selector objects are more performant than filter functions and should be preferred where possible (ie. when filtering on document attributes only).
- Using Filter Functions.
- filter functions exist on a design document. They are special functions that are called whenever there is an entry in the Changes Feed that matches some criteria.
- in principle they are like lambdas being triggered by some event.
Replications are created by either Writing documents to the _replicator database (preferred) or POSTing to the _replicate HTTP endpoint (legacy)
The first database of CouchDB used transient replication. Transient means that there are no documents backing up the replication— after a restart of the CouchDB server, the replication will disappear.
- this still exists for backward compatability purposes
- nowadays, persistent replication is used.
- Persistent means the
_replicatordatabase is used, which keeps documents containing your replication parameters.
- Persistent means the
Replication database
The _replicator database is like any other database in CouchDB, except for one feature: documents added to it will trigger replications
- there is a default
_replicatordatabase, but we can create our own.
through the _replicator database, we can control the persistent replication
- each document describes one replication process
Example document of _replicator database:
{
"_id": "rep_from_A",
"source": "http://aserver.com:5984/foo",
"target": {
"url": "http://localhost:5984/foo_a",
"auth": {
"basic": {
"username": "user",
"password": "pass"
}
}
},
"continuous": true
}
Replication scheduler
The scheduler manages the replication jobs as soon as they are created.
The scheduler is the replication component which periodically stops some jobs and starts others
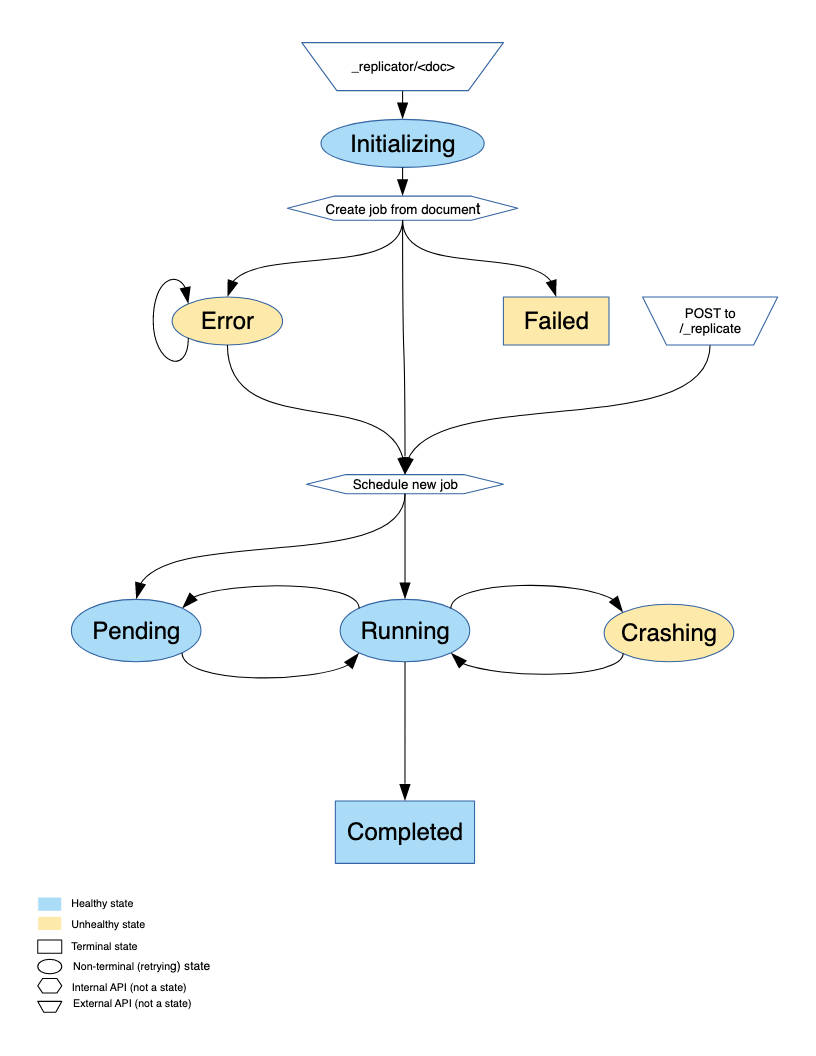
Replication Lifecycle (state machine)
Replication jobs during their life-cycle pass through various states. This is a diagram of all the states and transitions between them:
CouchDB replication does not have its own protocol. A replicator simply connects to two DBs as a client, then reads from one and writes to the other. Push replication is reading the local data and updating the remote DB; pull replication is vice versa.
- Fun fact 1: The replicator is actually an independent Erlang application, in its own process. It connects to both couches, then reads records from one and writes them to the other.
- Fun fact 2: CouchDB has no way of knowing who is a normal client and who is a replicator (let alone whether the replication is push or pull). It all looks like client connections. Some of them read records. Some of them write records.
A record's revision ID is the checksum of its own data. Subsequent revision IDs are checksums of: the new data, plus the revision ID of the previous.
Conflicts
When putting a new version of a document, the source must provide the previous _rev value that it has. If the target does not have the same _rev value, then it will throw a 409 Conflict error.
When the update conflict occurs, the client who errored out must fetch again, and then either
- apply the same changes as were applied to the earlier revision, and submit a new PUT
- redisplay the document so the user has to edit it again
- just overwrite it with the document being saved before (which is not advisable, as user1’s changes will be silently lost)
Backlinks