Lambda
The Lambda Architecture is a deployment model for data processing that organizations use to combine a traditional batch pipeline with a fast real-time stream pipeline for data access.
The goal is to become more data-driven and event-driven in the face of massive volumes of rapidly generated data, often referred to as “big data.”
Five main components to Lambda Architecture
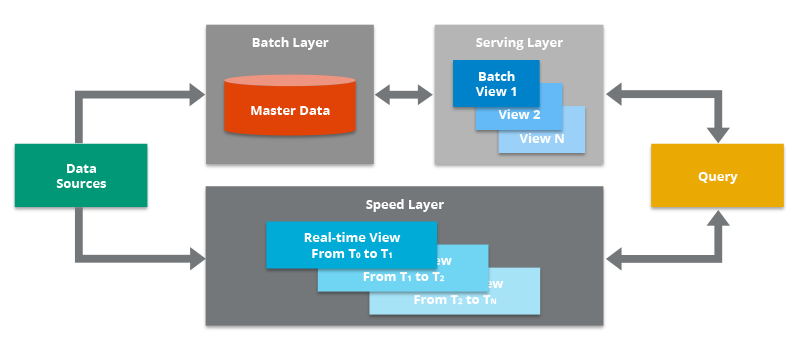
Data Sources - Data can be obtained from a variety of sources, which can then be included in the Lambda Architecture for analysis. This component is oftentimes a streaming source like Apache Kafka , which is not the original data source per se, but is an intermediary store that can hold data in order to serve both the batch layer and the speed layer of the Lambda Architecture. The data is delivered simultaneously to both the batch layer and the speed layer to enable a parallel indexing effort.
Batch Layer - This component saves all data coming into the system as batch views in preparation for indexing. The input data is saved in a model that looks like a series of changes/updates that were made to a system of record, similar to the output of a change data capture (CDC) system. Oftentimes this is simply a file in the comma-separated values (CSV) format. The data is treated as immutable and append-only to ensure a trusted historical record of all incoming data. A technology like Apache Hadoop is often used as a system for ingesting the data as well as storing the data in a cost-effective way.
Serving Layer - This layer incrementally indexes the latest batch views to make it queryable by end users. This layer can also reindex all data to fix a coding bug or to create different indexes for different use cases. The key requirement in the serving layer is that the processing is done in an extremely parallelized way to minimize the time to index the data set. While an indexing job is run, newly arriving data will be queued up for indexing in the next indexing job.
Speed Layer - This layer complements the serving layer by indexing the most recently added data not yet fully indexed by the serving layer. This includes the data that the serving layer is currently indexing as well as new data that arrived after the current indexing job started. Since there is an expected lag between the time the latest data was added to the system and the time the latest data is available for querying (due to the time it takes to perform the batch indexing work), it is up to the speed layer to index the latest data to narrow this gap.
- This layer typically leverages stream processing software to index the incoming data in near real-time to minimize the latency of getting the data available for querying. When the Lambda Architecture was first introduced, Apache Storm was a leading stream processing engine used in deployments, but other technologies have since gained more popularity as candidates for this component (like Hazelcast Jet, Apache Flink, and Apache Spark Streaming).
Query - This component is responsible for submitting end user queries to both the serving layer and the speed layer and consolidating the results. This gives end users a complete query on all data, including the most recently added data, to provide a near real-time analytics system.