Connect
Kafka Connect is Kafka's integration API and subsystem, and answers questions like:
- "how do we get data from other systems into our Kafka topics?"
- answer: source connectors
- "how do we get data from our Kafka topics into our other systems (sink)?"
- answer: sink connectors
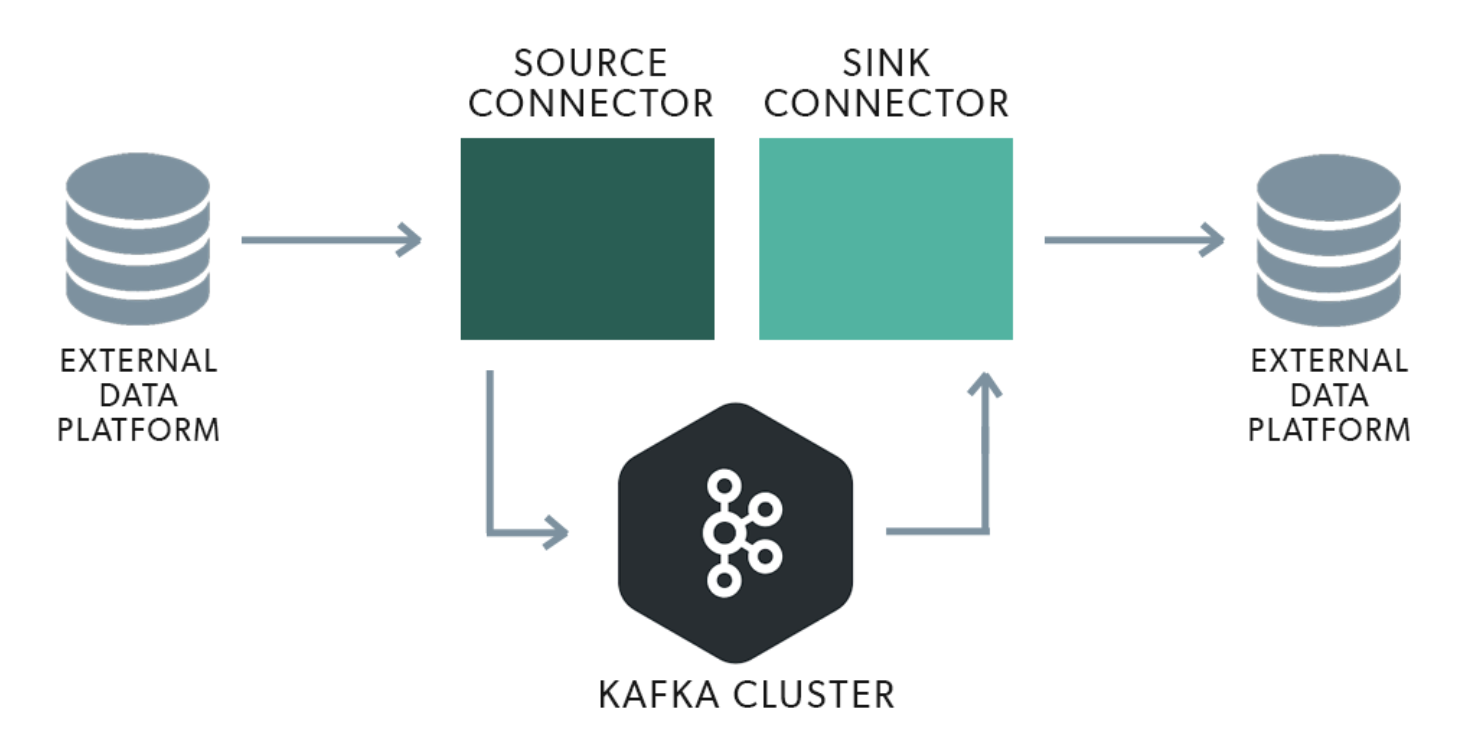
Kafka Connect is an ecosystem of pluggable connectors
- a connector is simply a
.JARfile
The job of many source/sink connectors is part of the well trodden path.
- that is, the code that moves data from a topic to an S3 bucket, from a topic to ElasticSearch, from a topic to records in a relational database is unlikely to vary from one business to the next.
Connect abstracts away much of the data integration code, and allows us to write JSON config in its place.
- ex. the following JSON is how we would stream data from Kafka into ElasticSearch
- by doing this, we no longer need to write the code that subscribes to a topic, gets messages, and uses the ElasticSearch API
- As long as someone has already written an ElasticSearch connector, we can deploy that connector to our Connect cluster and POST the JSON file to the REST endpoint of the Connect cluster. By doing this, the
.JARfile that is deployed to the cluster becomes instantiated as a runtime connector.
{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"name": "simple-elasticsearch-connector",
"connection.url": "http://elasticsearch:9200",
"type.name": "_doc"
}
To a Kafka cluster, Connect looks like a producer or consumer (or both)
Connect runs on hardware that is independent of the Kafka brokers themselves.
Connect is designed to be scalable and fault-tolerant
- this means we can have a cluster of Connect workers to share the load of moving data in and out of Kafka topics.
Worker
A Connect Worker is a node in the Connect cluster.
The worker runs 1+ Connectors.